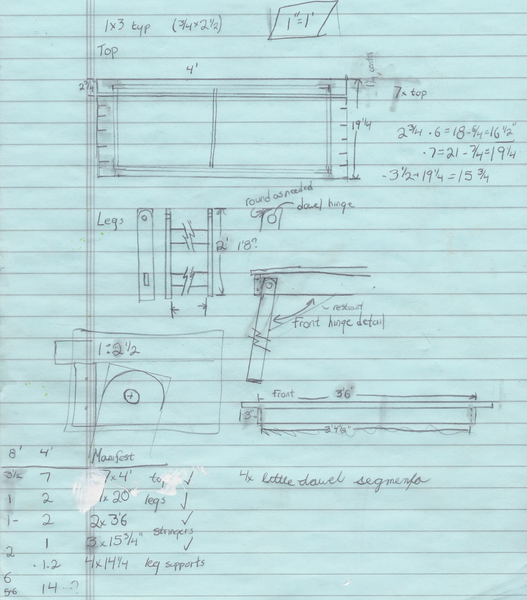
One of the most important sensors on the robot is a depth sensor, used to pick out obstacles blocking the robot. If the obstacles were uniform, color and pattern matching would suffice, but they're massively varied. The course includes garbage cans (tall, round, green or gray), traffic cones (short, cone, orange), construction barrels (tall, cylindrical, orange), and sawhorses (they look different from every side). Sophisticated computer vision could pick them out, but a depth sensor can easily separate foreground and background.
Most teams use LIDAR. These expensive sensors send a ping of light and time the echo. Time is converted to distance, and the ping is swept 180 degrees around the robot. We can't afford LIDAR. Our depth-sensing solution is divergence mapping. The sensing works in much the same way as a human eye: two cameras, a small distance apart, capture images synchronously. The images are compared, and their small differences are used to find depth. People do it subconsciously; the computer searches for keypoints (features that it can identify between frames). The matching fails on uniform surfaces, but works well on textured ones. (Like grass; isn't that convenient?)
 The depthmap can only be generated when the images match closely. That means that the cameras need to be fixed relative to each other, and the images need to be taken simultaneously.
The depthmap can only be generated when the images match closely. That means that the cameras need to be fixed relative to each other, and the images need to be taken simultaneously.


























 show strong responses.")